Как и обещал, открою новую тему, где можно будет обсудить все прелести борьбы с ошибками в каналах передачи данных.
Как известно, во время передачи данных по любым каналам связи, в передаваемые данные вносятся ошибки, что приводит к искажению передаваемой информации. Причины ошибок могут быть самыми ращличными, начиная от помех и сбоев оборудования и заканчиая некомпетентностью/плохим настроением персонала, использующего эти средства связи.
Для борьбы с вносимыми искажениями используются различные способы, которые в общем можно разбить условно на две большие группы:
1. Автоматический запрос повторной передачи (ARQ — Automatic Repeat reQuest)
2. Непосредственное исправление ошибок (FEC - Forward Error Correction)
ARQ При автоматическом запросе повторной передачи передаваемые данные разбиваются на блоки. На принимающей стороне проверяется отсутствие ошибок в переданном блоке. Если в блоке данных обнаружена ошибка, отправляется запрос на передающую сторону для повторной передачи данных. В ответ на этот запрос передающая сторона повторяет передачу.
Таким образом, для этого метода достаточно использовать лишь обнаружение ошибок.
FEC Для непосредственного исправления ошибок используются специальные коды (Рида-Соломона, турбокоды, БЧХ, и т.д.). Данные коды за счет своей структуры позволяют не только обнаружить, но исправить ошибки в полученных данных. Но исправление возможно лишь в том случае, если число ошибок не превышает исправляющую способность кода.
Основы проверки и справления ошибок
Существующие методы проверки и исправления ошибок основаны на добавлении к информационным данным дополнительных данных, т.н. проверочой части. Таким образом в передаваемые данные вносится избыточность, что приводит к уменьшению скорости передачи именно информации.
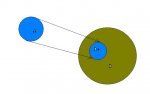
В результате внесения избыточности, множество А всех возможных информационных слов превращается во множество всех разрешенных кодовых слов B+, которое является подмножеством B. Поскольку в информационные данные добавили проверочные (дополнительные) данные, то мощность множества B больше мощности множества А. См рисунок ниже.
При передаче информации, информационное слово aиз множества А дополняется проверочными данными. В результате получаем разрешенное кодовое слово из множества B+. На приемной стороне, принятое кодовое слово a_, которое может отличаться от переданного, проверяется на входимость в множество B+. Итак, если оно пренадлежит этому множеству, то принимается решение, что информация передана правильно и производится преобразование по получению информационной части кодового слова. Если же полученное слово не принадлежит множеству B+, то принимается решение, что в ходе передачи были внесены ошибки, и если код позволяет исправлять ошибки, проводится их исправление.
Стоит заметить, что в процессе передачи данных, в передаваемое кодовое слово внесуться такие ошибки, что оно все равно будет принадлежать множеству B+ и ошибки не обнаружатся. Это говорит о том, что у используемого метода слабая исправляющая/проверочная способность.
Как известно, во время передачи данных по любым каналам связи, в передаваемые данные вносятся ошибки, что приводит к искажению передаваемой информации. Причины ошибок могут быть самыми ращличными, начиная от помех и сбоев оборудования и заканчиая некомпетентностью/плохим настроением персонала, использующего эти средства связи.
Для борьбы с вносимыми искажениями используются различные способы, которые в общем можно разбить условно на две большие группы:
1. Автоматический запрос повторной передачи (ARQ — Automatic Repeat reQuest)
2. Непосредственное исправление ошибок (FEC - Forward Error Correction)
ARQ При автоматическом запросе повторной передачи передаваемые данные разбиваются на блоки. На принимающей стороне проверяется отсутствие ошибок в переданном блоке. Если в блоке данных обнаружена ошибка, отправляется запрос на передающую сторону для повторной передачи данных. В ответ на этот запрос передающая сторона повторяет передачу.
Таким образом, для этого метода достаточно использовать лишь обнаружение ошибок.
FEC Для непосредственного исправления ошибок используются специальные коды (Рида-Соломона, турбокоды, БЧХ, и т.д.). Данные коды за счет своей структуры позволяют не только обнаружить, но исправить ошибки в полученных данных. Но исправление возможно лишь в том случае, если число ошибок не превышает исправляющую способность кода.
Основы проверки и справления ошибок
Существующие методы проверки и исправления ошибок основаны на добавлении к информационным данным дополнительных данных, т.н. проверочой части. Таким образом в передаваемые данные вносится избыточность, что приводит к уменьшению скорости передачи именно информации.
В результате внесения избыточности, множество А всех возможных информационных слов превращается во множество всех разрешенных кодовых слов B+, которое является подмножеством B. Поскольку в информационные данные добавили проверочные (дополнительные) данные, то мощность множества B больше мощности множества А. См рисунок ниже.
При передаче информации, информационное слово aиз множества А дополняется проверочными данными. В результате получаем разрешенное кодовое слово из множества B+. На приемной стороне, принятое кодовое слово a_, которое может отличаться от переданного, проверяется на входимость в множество B+. Итак, если оно пренадлежит этому множеству, то принимается решение, что информация передана правильно и производится преобразование по получению информационной части кодового слова. Если же полученное слово не принадлежит множеству B+, то принимается решение, что в ходе передачи были внесены ошибки, и если код позволяет исправлять ошибки, проводится их исправление.
Стоит заметить, что в процессе передачи данных, в передаваемое кодовое слово внесуться такие ошибки, что оно все равно будет принадлежать множеству B+ и ошибки не обнаружатся. Это говорит о том, что у используемого метода слабая исправляющая/проверочная способность.
Вкладення
-
 sets.JPG14.3 КБ · Перегляди: 164
sets.JPG14.3 КБ · Перегляди: 164
